
Have you ever worried about duplicate content?
It could be anything: some boilerplate text on your web site. Or, a product description on your e-commerce web page you borrowed from the original seller. Or, maybe a quote you copied from your favorite blog post or an authority in your niche.
No matter how hard you try to offer 100% unique content, you can’t.
Duplicate content is among the top 5 SEO issues that sites face especially now Google has put its Panda Update into play.

It’s true: you CAN’T remove all instances of duplicate content on your web pages, even when you use the rel canonical tag url parameter.
Google’s Matt Cutts has himself stated that duplicate content happens all over the net all the time, from blog posts to web pages and social media. Cutts stated,
And Google gets it.
Therefore, there’s no such thing as GOOGLE’S DUPLICATE CONTENT PENALTY.
Yes, you read it right.
Google doesn’t penalize web sites that use duplicate content. That Google goes after sites that have X% duplicate content is another SEO myth.
Now, you’re probably wondering: if Google doesn’t penalize web sites that have duplicate content, what’s all the fuss about? Why the need for rel canonical tags and content management to ensure that you don’t have duplicates?
While Google doesn’t penalize sites for duplicate content, it does discourage it. Let’s see why Google discourages duplicate content and their Panda Update, and then look at the different ways to resolve the duplicate content issue(s) on your site. From URL parameters to canonical tags and session ID’s, there are many ways to reduce your duplicate content problems.
Before we begin, let’s see how Google defines duplicate content.
What is duplicate content
Here’s Google’s definition of duplicate content:
Duplicate content generally refers to substantive blocks of content within or across domains that either completely match other content or are appreciably similar.
As you can understand from Google’s definition, Google identifies two types of instances of duplicate content: the first type that happens on the same domain and the other type that happens across multiple domains.
Here are a few examples to help with understanding duplicate content and the different types.
Instances of duplicate content on the same domain
As you can tell, this type of duplicate content happens within your e-commerce site, blog posts, or web site.
Think of such duplicate content as the same content that appears in different web pages on your site.
It could be that:
- This content is present on your site in different locations (URLs).
- Or, perhaps it’s reachable through different ways (hence resulting in different URL parameters). For example, these could be the same posts that are shown when a search is done based on the different categories and tags on your site.
Let’s look at some examples of different types of duplicate content on the same site.
Boilerplate content:
Simply put, boilerplate content is available on different sections or web pages on your site.
Ann Smarty classifies Boilerplate content as:
- (Sitewide) global navigation (home, about us, etc)
- Certain special areas, especially if including links (blogroll, navbar)
- Markup (javascript, CC id/class names such as header, footer)
If you look at a standard site, it will usually have a header, a footer and a sidebar. In addition to these elements, most CMS’ allow you to show your most recent posts or your most popular posts on your homepage as well.
When search bots crawl your site, they will get that this content is present several times on your site, and so, it is indeed duplicate content.
But this type of duplicate content doesn’t harm your SEO. Search engine bots are sophisticated enough to understand that the intention behind this content duplication is not malicious. So, you’re safe.
Inconsistent URL structures:
Look at the following URLs –
www.yoursite.com/
yoursite.com
https://yoursite.com
https://yoursite.com/
https://www.yoursite.com
https://yoursite.com
Do they look the same to you?
Yes, you’re right, the target URL is the same. So, to you, they mean the same thing. Unfortunately, search engine bots read these as different URLs.
But, when search engine bots come across the same content on two different URLs: https://yoursite.com and https://yoursite.com, they consider it as duplicate content.
This problem applies to URL parameters generated for tracking purposes as well:
https://yoursite.com/?utm_source=newsletter4&utm_medium=email&utm_campaign=holidays
URL parameters with tracking can also cause duplicate content issues.
Localized domains:
Suppose you cater to different countries and have created localized domains for each country you serve.
For example, you might have a .de version of your site for Germany and a .au version for Australia.
It’s natural that the content will overlap on both of these sites. Unless you translate your content for the .de domain, search engines will find your content to be duplicate across both the sites.
In such cases, when a searcher looks for your business, Google will show either of these two URLs.
Google often sees the status of the searcher. Suppose the searcher were present in Germany. Google would, by default, show only your .de domain. However, Google might not get it right.
Instances of duplicate content on different domains
Copied content:
Copying content from a site (without permission) is wrong and Google considers it so. If you offer nothing but duplicate content, your site will be at risk especially now the Panda Update is in play. Google may not show it in the search results at all or throw your web site off the first few pages of the results.
Content curation:
Content curation is the process of looking for stories and creating blog posts that are relevant to your readers. These stories could be from anywhere on the Internet – from web pages to social media.
Since a content curation post compiles a list of content pieces from around the web, it’s natural that the post contains duplicate content (even if it’s just duplicate titles). Most blog posts borrow excerpts and quotes as well.
Again, Google’s doesn’t see this as SPAM.
As long as you provide some insight, a fresh perspective or explain things in your own style, Google will not view this content duplication as malicious leaving you free from the worry of having to add on rel canonical tags, session ID’s, and the rest.
Content syndication:
Content syndication is increasingly becoming a mainstream content management tactic. Curata found that the ideal content marketing mix carried a 10% contribution from syndicated content.
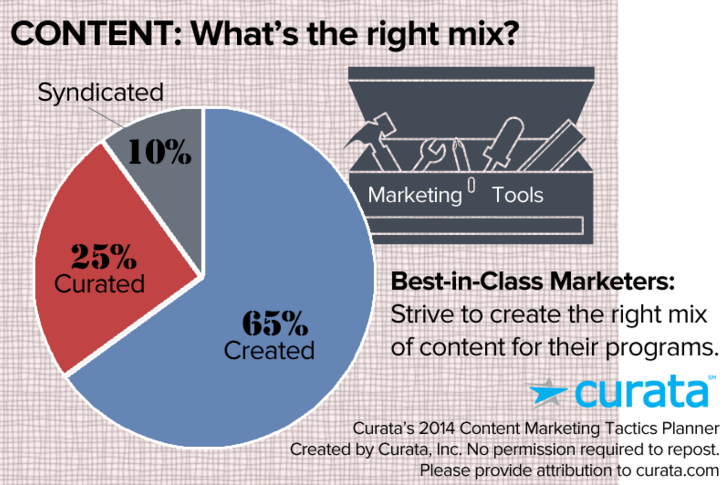
As Search Engine Land puts it, “Content syndication is the process of pushing your blog, site or video content out into third-party sites, as a full article, snippet, link or thumbnail.”
Sites that syndicate content offer their content to be published on several sites. This means that several copies exist of any syndicated post. This is also true of social media.
If you’re familiar with the Huffington post, you’ll know that it allows content syndication. Every day it features stories from all over the web and republishes them with permission.
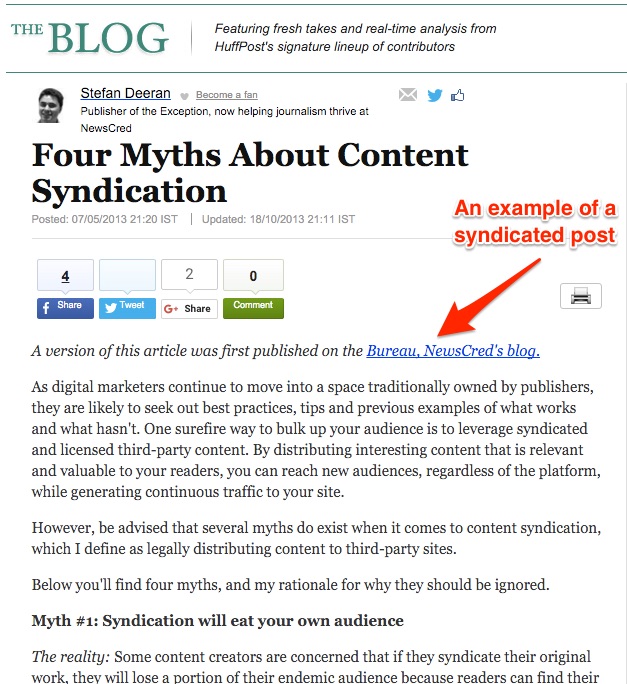
Buffer also syndicates content. Their content gets republished on sites like the Huffington Post, Fast Company, Inc. and more.
The following screenshot shows the traffic that such syndicated content brings to their site.
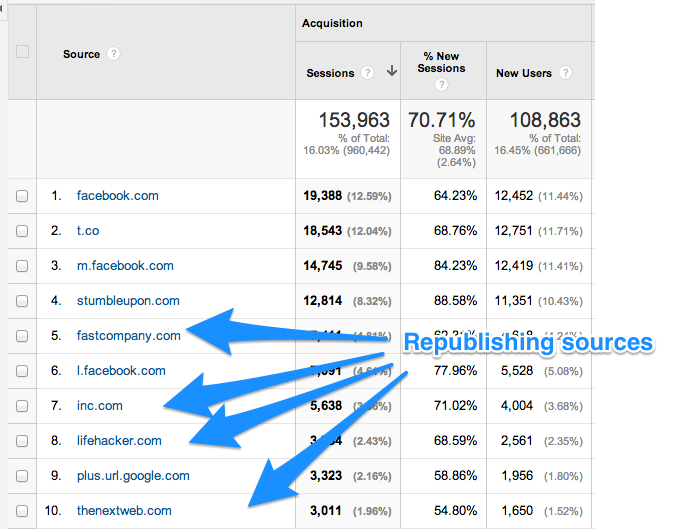
While these instances are counted as duplicate content, Google doesn’t penalize them.
The best way to syndicate content is to ask the republishing sites to declare you as the original content creator and also that they link back to your site with appropriate anchor text, i.e., to the original content piece.
Content scraping:
Content scraping is always a gray area when you’re discussing duplicate content issues.
Wikipedia defines web scraping (or content scraping) as:
Web scraping (web harvesting or web data extraction) is a computer software technique of extracting information from sites.
Interestingly, even Google scraps data to offer it immediately on the first SERP.
So, it’s no wonder that Matt Cutt’s tweet,
If you see a scraper URL outranking the original source of content in Google, please tell us about it…
created quite a bit of noise.
Dan Barker responded with this tweet:
@mattcutts I think I have spotted one, Matt. Note the similarities in the content text:
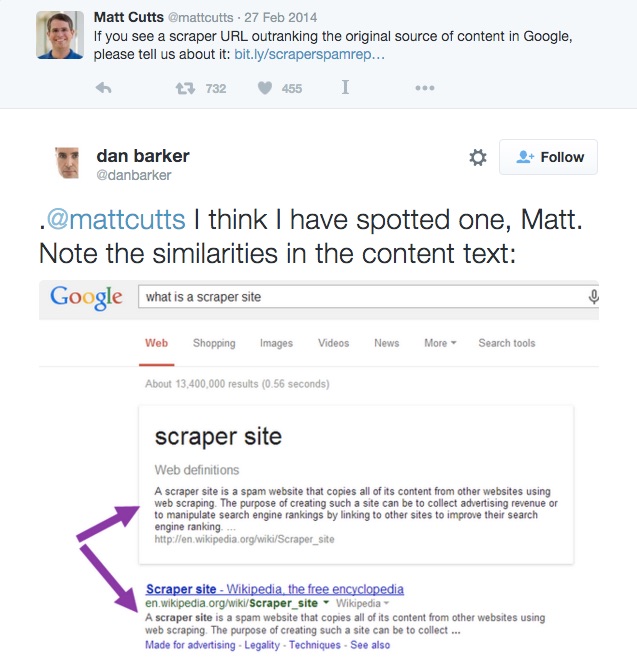
As you can see. Google fetches content from the top result and shows it directly on the SERP. This is, without a doubt, content scrapping.
So, discarding scraping as content malpractice won’t be right in all cases.
However, if you go a little deeper, you will see that Google doesn’t tolerate content scraper sites, as addressed in their Panda Update.
Now that you have a reasonable idea about what counts as duplicate content, let’s look at the instances that aren’t cases of duplicate content, yet webmasters often worry about them.
What’s not counted as duplicate content
Translated content:
Translated content is NOT DUPLICATE content. If you have a site and you have localized it for different countries and translated your main content into the local languages, you will not face any content duplication issues.
But, this example is not so straightforward. If you use some software, webmaster tools, or even Google’s translator for the translation, the quality of the translation will not be perfect.
And, when the translation doesn’t make natural sense and lacks a personal review, Google might look at the content as spammy, duplicate content.
Such content can be easily identified to be software-generated and can raise flags with Google.
The best way to avoid this problem is to get a human translator to do the job. Or, do a decent job with some good software and then have it reviewed by a professional translator.
By reviewing the translated content, you will ensure that the content quality is top notch and Google will not think of it as duplicate content.
But, if for some reason you cannot do either of the two, then you should block the software-translated content from being reviewed by the bots using robots.txt. (I will show you how to do this in the following sections.)
Mobile site content:
If you don’t have a responsive site, it might be that you have developed a separate mobile version for your main site.
So, you’ll have different URLs serving the same content, like:
http:yoursite.com – Web version
http.m.yoursite.com – Mobile version
Having the same content on your web and mobile site versions does not count as duplicate content. Also, you must know that Google has different search bots that crawl mobile sites, so you don’t have to worry about this case.
Google can identify instances of duplicate content that are done with malicious intent. You’re never at risk if you’re not trying to game the system. But, you should still avoid instances of duplicate content as they do impact your SEO.
Here’s how duplicate content can make your SEO suffer:
Problems caused by duplicate content
Problem #1 – Link popularity dilution
When you don’t set a consistent URL structure for your site, you end up creating and distributing different versions of your site links as you start link-building.
To understand this better, imagine that you have created an epic resource that has produced a ton of inbound links and traffic from lots of session IDs.
Yet, you don’t see the page authority of that original source rise as much as you expected.
Why didn’t the page authority shoot up, despite all the links and traction?
Perhaps it didn’t because different backlinking sites linked back to the resource using different versions of the resource URL.
Like:
https://www.yoursite.com/resource
https://yoursite.com/resource
https://yoursite.com/resource
and so on…
Do you see how not understanding duplicate content management ruined your chances of creating a higher authority page?
All because search engines could not interpret that all the URLs pointed to the same target location.
Problem #2 – Showing unfriendly URLs
When Google comes across two identical or appreciably similar resources on the web, it chooses to show one of them to the searcher. In most cases, Google will select the most appropriate version of your content. But, it doesn’t get it right every time.
It may happen that for a particular search query, Google might show a not-so-great-looking URL version of your site.
For example, if a searcher were looking for your business online, which one of the following URL parameter options would you like to show to your visitor:
https://yoursite.com
or https://yoursite.com/overview.html
I think you would be interested in showing the first option.
But, Google might just show the second one.
If you avoided the instance of duplicate content in the first place, there wouldn’t have been this confusion and the user would only see the best and most branded version of your URL.
Problem #3 – Zapping search engine crawler resources
If you understand how crawlers work, you know that Google sends its searching meta robots to crawl your site depending upon your frequency of publishing fresh content.
Now, imagine that Google crawlers visit your site and they crawl five URLs only to find all of them offering the same content.
When search bots discover and index the same content on different places on your site, you lose crawler cycles. By understanding duplicate content, the search bots will not crawl over your new content.
These crawler cycles could have otherwise been used to crawl over and index any freshly published content that you might have added to your site. This won’t just waste crawler resources but will also hurt your SEO.
How does Google handle duplicate content
When Google finds identical content instances, it decides to show one of them. Its choice of the resource to display in the search results will depend upon the search query.
If you have the same content on your site and offer its print version as well, Google will consider if the searcher is interested in the print version. If so, only the print version of the content will be fetched and presented.
You might have noticed messages on a SERP indicating that other similar results were not shown. These happen when Google chooses one of the several copies of the similar content on different web pages.
Duplicate content is not always treated as SPAM. It becomes a problem only when it’s aimed to abuse, deceive and manipulate the search engine rankings.
Google takes duplicate content seriously and can even ban your site if you try to trick the search engine using duplicate content.
Google’s duplicate content policy states:
In the rare cases in which Google perceives that duplicate content may be shown with intent to manipulate our rankings and deceive our users, we’ll also make appropriate adjustments in the indexing and ranking of the sites involved. As a result, the ranking of the site may suffer, or the site might be removed entirely from the Google index, in which case it will no longer appear in search results.
As you saw above, most instances of duplicate content happen unintentionally. Even you could be using boilerplate text on your site. Also, it could be that different sites, social media or blog posts are copying and republishing your content without your permission.
There are different ways you can check your site for duplicate content issues. Let’s look at a few options.
How identify duplicate content issues
Method #1: Do a simple Google search
The easiest way to detect duplicate content issues within your site is to do a simple Google search.
Just search for a keyword that you rank for and observe the search engine results. If you find that Google is showing a non-user-friendly URL of your content, then you have duplicate content on your site.
Method #2: Look for alerts in Google Webmasters
The Google Search Console webmaster tool also proactively alerts you about instances of duplicate content on your site.
To find Google alerts about duplicate content, login to your Google Webmasters account. If you’re already logged in, you can simply click on this link.
Method 3: Check out the Crawler metrics in your Webmasters dashboard
The crawler metrics show the number of pages that Google crawlers crawled on your site.
If you see crawlers crawling and indexing hundreds of pages on your site while you just have a few, you’re perhaps using inconsistent URLs or anchor text, or not using rel canonical tags. And, therefore, search engine crawlers are crawling over the same content multiple times at different URLs.
To see the Crawler metrics, login to your Google Webmasters account, click on the Crawl option on the left panel. Under the expanded menu, click on the Crawl Stats option.
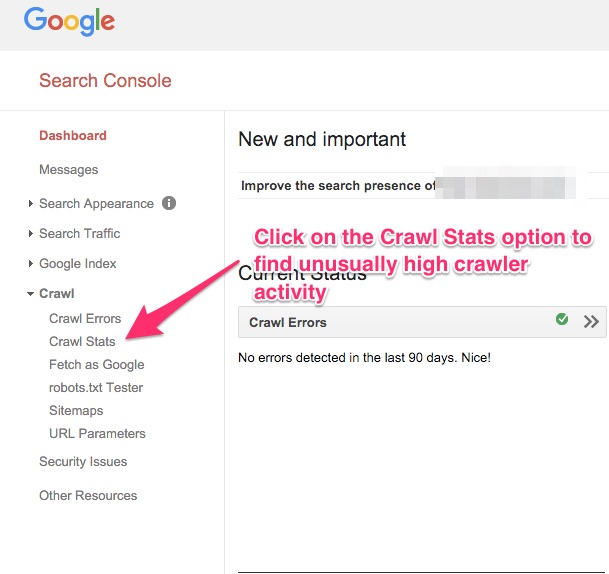
If you see some unusually high search crawler activity when using this webmaster tool, you should check your URL structure and see if your site is using inconsistent URLs.
Method 4: Screaming Frog
Screaming Frog is a desktop SEO audit webmaster tool that crawls your site just like search crawlers. You can catch several types of duplicate content and URL parameter issues with it.
Steps to use Screaming Frog to find duplicate content issues:
1. Visit the Screaming Frog official site and download a copy that’s compatible with your system.
Please note that Screaming Frog’s free version can be used to crawl up to 500 web pages. That’s enough for most sites.
2. Once you’ve installed the program, open it and enter your site’s URL. Click start.
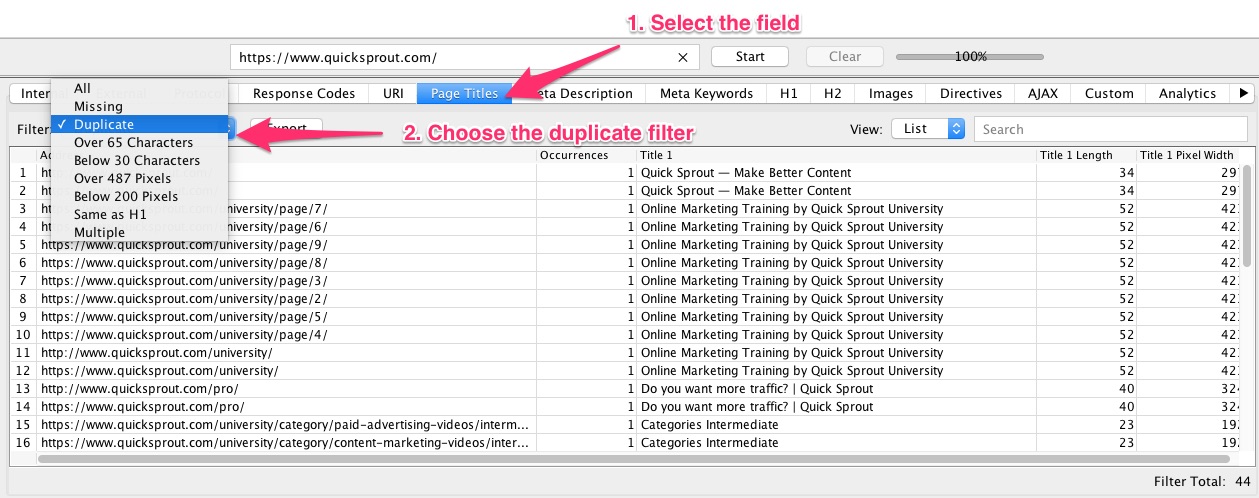
3. Once Screaming Frog crawls your site, you can click on the field that you want to check for duplicate content, such as URLs, page titles, anchor text, meta descriptions and so on.
After selecting the field, choose the duplicate filter. Using this method, you can detect all of the occurrences of duplicate content on your site.
Method 5: Search for blocks of content
This method is a bit crude, but if you suspect that your content is being copied on different sites or blog posts, or is present on different places on your site, you could also try this.
Copy a random text block from your content and do a simple Google search. Remember to not use long paragraphs, as they will return an error.
Pick a 2-3 sentence paragraph and look for it on Google.
If the search results show different sites posting your content, you’re probably a victim of plagiarism.
Using the above methods, you can easily identify duplicate content issues on your site. Now, let’s take a look at some solutions to handle the duplicate content issues.
4 solutions for treating the duplicate content problem
1. Consistency
As you saw in the earlier section, a majority of instances of duplicate content happen when the URL structure is inconsistent.
Your best solution here is to standardize your preferred link structure, as well as proper use of canonical tags. It could be the www or the non-www version. Or maybe the HTTP or the HTTPs version — whatever it is, it needs to be consistent.
You can tell Google about your preferred URL version by setting your preference in your Google Webmasters account.
After logging in, click on the settings gear on top right corner. Then, select Site Settings.
Here you can see the option to set your preferred domain:
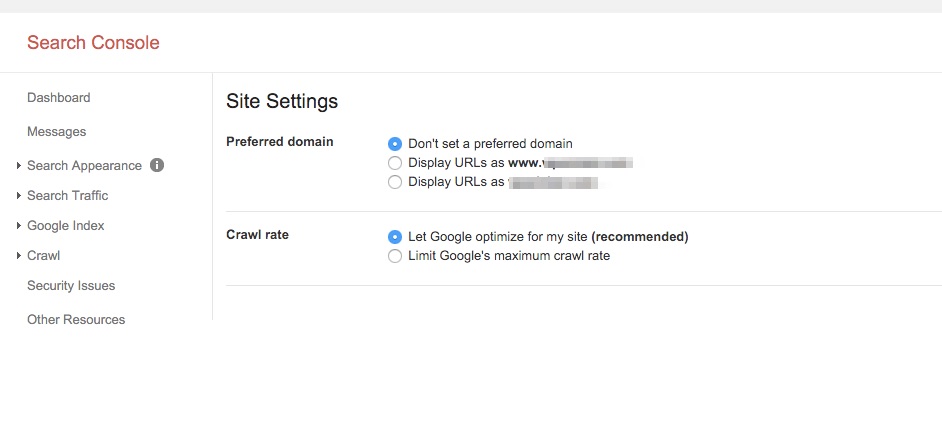
Benefits of setting the preferred domain:
- Sorts duplicate content issues with the www and non-www version
You now know that Google bots treat yoursite.com and www.yoursite.com as two different pages and counts the same content on them as duplicate content.
By simply setting your preferred domain, you can ask Google to just crawl and index one of them and you also remove all risk of duplicate content.
- Retains link juice
Setting a preferred domain helps your site retain the link juice even when a backlinking site links to a non-preferred version of your site.
An excerpt from Google’s resource:
For instance, if you specify your preferred domain as https://www.example.com and we find a link to your site that is formatted as https://example.com, we follow that link as https://www.example.com instead.
In addition, we’ll take your preference into account when displaying the URLs. If you don’t specify a preferred domain, we may treat the www and non-www versions of the domain as separate references to separate pages.
Google’s preferred domain option pretty much takes care of the inconsistencies with the www and the non-www version of your site.
After setting your preferred domain in Google Webmaster Tools, your next step should be to set up 301 redirects from all of the non-preferred domain links on your site to your preferred ones. This will help search engines and visitors learn about your preferred version.
However, there can be other inconsistencies that I mentioned above. To sort those out, you should not just choose a preferred version of the URL, but also choose the exact syntax and URL parameters that your team should use when linking to any content on your site.
You can also have a style guide that can be distributed internally to show the standard way of sharing URLs. Basically, whenever you share a link to any page or post on your site, you should make sure that the same link format and anchor text goes out each time.
Remember that search engines could treat these web pages differently: https://www.yoursite.com/page/ and https://www.yoursite.com/page and https://www.yoursite.com/page/index.htm. So choose one and keep it consistent.
2. Canonicalization
Most CMSes allow you to organize your content using tags and categories. Often when users perform tag or category-based searches, the same results show up. As a result, the search engine bots might think that both the URLs offer the same content.
https://www.yoursite.com/some-category
and
https://www.yoursite.com/some-tag
This problem is more serious in e-commerce sites where a single product can be reached using multiple filters (thus resulting in several possible URL parameters).

It’s true that categories, tags, filters and search boxes help you organize your content and make it easy for your on-site visitors to find what they need.
But, as you can see in the above screenshot, such e-commerce site searches result in multiple URL parameters and thus cause duplicate content issues.
When people look for content on Google, these multiple links can confuse Google’s Panda Update bots and Google might end up showing a non-friendly version of your resource, like https://www.yoursite.com/?q=search term in the search results.
To avoid this problem, Google recommends that you add a canonical tag to the preferred URL of your content.
When a search engine bot goes to a page and sees the canonical tag, it gets the link to the original resource. Also, all links to any duplicate page are counted as links to the original source page. So, you don’t lose any SEO value from those links.
Canonical tags can be implemented in several ways:
Method 1: Set the preferred version: www and the non-www
Setting the preferred version of your domain, as we discussed in the above section, is also a form on canonicalization.
But, as you can understand, it only addresses a very broad issue. It doesn’t handle duplicate content issues that CMS’s generate.
Method 2: Manually point to the canonical link for all the pages
In this method, you should start by defining your original resource. The original resource is the web page that you want to make available to your readers every time they search.
The original resource is also the page that you want to set as your preferred page to signal to the search engine bots. This can be achieved using canonical tags.
Use the methods listed in the above section to identify instances of duplicate content on your site. Next, identify pages that offer similar content and choose the original resource for each.
After the above two steps, you’re ready to use the canonical tag.
To do so, you will have to access the source code of the resource, and in its <head> tag, add the following line:
<link rel=”canonical” href=”https://yoursite.com.com/category/resource” />
Here, “https://yoursite.com.com/category/resource” is the page that you want to call the original resource.
You will follow the same process of adding rel canonical tags on every similar page.
My blog at CrazyEgg supports categories. So the posts are accessible via the homepage blogroll as well as through the different categories.
I use the rel=canonical tag to mark my preferred URL for each page and post.
Look at the following screenshot showing the tag:
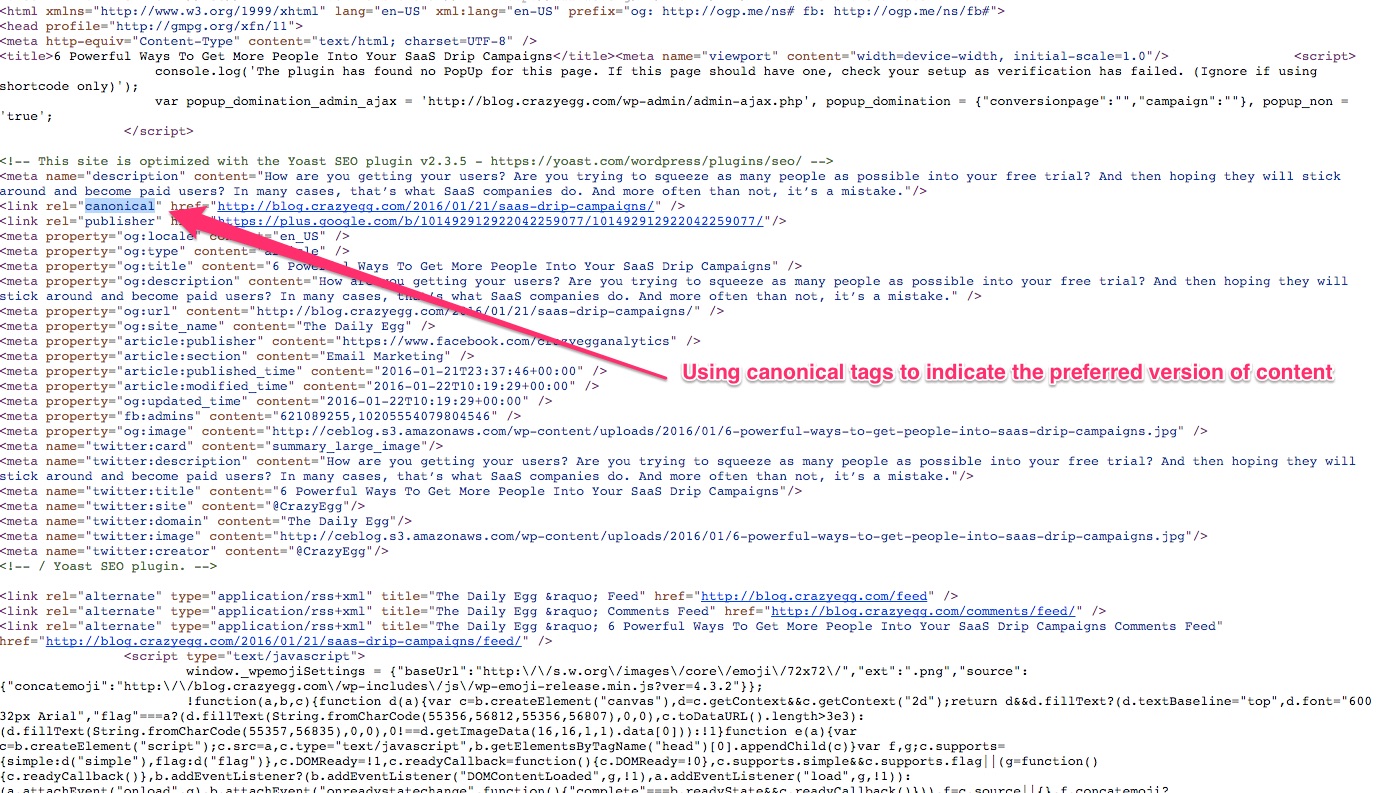
Using the canonical tag is an easy way to tell Google about the link you’d like Google to show to the users when they search.
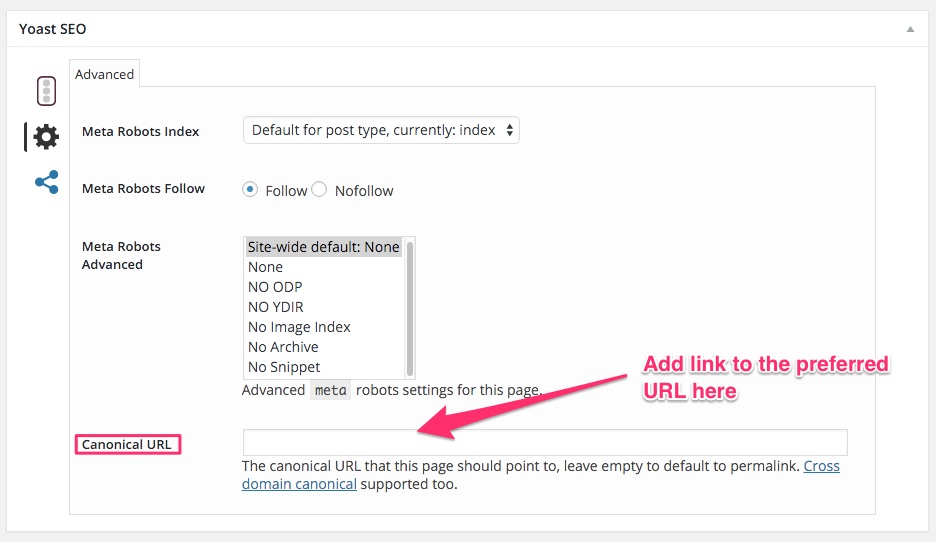
As you can probably tell, my site is built on WordPress and I’m using the Yoast SEO plugin. This plugin lets you set your preferred version of each page and post. So, you don’t have to worry about your post being reachable or showing up on different URLs.
If your site is built on WordPress, I’d recommend that you install this plugin. You can find the canonical tag URL option under the advanced plugin settings.
If a post or page that you create is itself the preferred version, leave the Canonical URL tag blank. If it’s not, add a link to the preferred resource in the Canonical URL field.
Method 3: Set up 301 redirects
Often, restructuring of sites results in duplicate content issues. Restructuring a link format too can create multiple copies of the same content.
To reduce the impact of such duplicate content issues, set up 301 redirects. 301 redirects from the non-preferred URLs of a resource to their preferred URLs are a great way to alert the search engines about your preference.
When a search engine bot goes to a page and sees a 301 redirect, it reaches the original resource via the duplicate content page. In such cases, all the links to the duplicate page are treated as links to the original page (no SEO value is lost).
Depending on your site, you could use these different ways to set up 301 redirects. If you have any questions about setting up redirects, your webhost should be able to help.
If you use WordPress, you can use a plugin like Redirection to create 301 redirects.
Whatever method you choose, I’d suggest running a test for broken links as configuring redirects can go wrong.
3. Noindex meta tag
Meta tags are a way for webmasters to give the search engines important information about their sites.
The noindex meta tag tells the search engine bots to not index a particular resource.
People often confuse the noindex meta tag with the nofollow meta tag. The difference between them is that when you use the noindex and nofollow tag, you’re asking the search engines to not index and follow the page.
Whereas when you use the noindex and follow tags, you’re requesting the search engines to not index the page but to not ignore any links to/from the page.
You can use the noindex meta tag to avoid having search engines index your pages with duplicate content.
To use the meta tag to handle instances of duplicate content, you should add the following line of code within your duplicate content page’s head tag.
<Meta Name=”Robots” Content=”noindex,follow”>
Using the follow tag along with the noindex tag makes sure that search engines don’t ignore the links on the duplicate pages.
4. Use the hreflang tag to handle localized sites
When you use translated content, you should use the hreflang tag to help the search engines choose the right version of your content.
If you have your site in English and you have translated it into Spanish to serve the local audience, you should add the tag, “<link rel=”alternate” href=”https://example.com” hreflang=”en-es” />” to the Spanish version of your site.
You should follow the same process for all of the different localized versions of your site. This will remove the risk of search engines considering it as duplicate content and will also improve the user experience when users want to interact with your site in their native language, determined by their session ID.
5. Use the hashtag instead of the question mark operator when using UTM parameters
It’s common to use tracking URL parameters like the source, campaign and medium to measure the effectiveness of different channels.
However, as we discussed earlier, when you create a link like https://yoursite.com/?utm_source=newsletter4&utm_medium=email&utm_campaign=holidays, search engines crawl it and report instances of duplicate content.
An easy workaround is to use the # operator rather than the question mark. When search engine bots come across the # sign in a URL, they ignore all that follows the sign, thereby avoiding duplicate content issues.
6. Be careful with content syndication
If you allow different sites to republish your content, always ask them to link back to your site, with accurate anchor text. Requesting the republishing sites to use the rel tag or the noindex tag could also help you prevent duplicate content issues caused due to republishing.
How not to treat duplicate content
As I have been saying, duplicate content happens all of the time. If you too have found your site to contain any instances of duplicate content, you must fix them. I’ve already shown you different ways to do so.
However, now I would like to show you some ways that are not correct and should not be used to fix duplicate content issues.
1. Don’t block URLs with robots.txt
First what is robots.txt? Robots.txt is a text file that has messages that you want to communicate to the search engine crawlers. These messages could be to request that the search crawlers not index specified URLs.
Some webmasters specify URLs that contain duplicate content in the Robot.txt files, and thus try to block search engines from crawling.
Google’s Panda Update discourages practices that block crawlers in any way. When pages are blocked from crawling, Google bots count them as unique pages, whereas they should know that they aren’t unique pages, but simply pages with duplicate content.
The second issue with this type of blocking is that other sites might still be able to link to a blocked page. If a high-quality site links to a blocked page and if the search engine bots don’t crawl or index that page, you will not get the SEO benefit of that backlink.
Besides, you can always mark duplicate pages as duplicate using the “canonical” tag.
2. Don’t spin (or rephrase) content to make it “unique”
Google bots can tell if your content is spun or bot-generated. So, spinning content or just rephrasing it to make it look unique won’t help.
Posting spun content will indicate to the search engines that you practice shady tactics to manipulate search rankings. This could result in Google taking action against your site.
3. Don’t use “remove URL” option in Google Webmasters
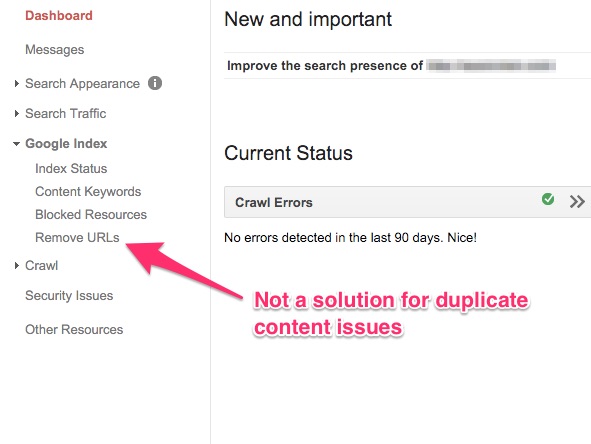
If you have noticed, Google Webmasters tools gives you the option to remove URLs from your site.
So, quite a few webmasters choose a non-friendly version of their resource that shows up in the search results and remove it using the above option.
The problem with this solution is that the URLs only get removed temporarily. And, your site will still face all the issues that I mentioned above. This one is not a solution at all.
This feature is helpful when you want to remove something from your site and want a quick fix until you work on the site to resolve it. It doesn’t help with duplicate content issues.
Conclusion
Most duplicate content issues can be avoided or fixed. Understanding duplicate content will affect your search engine rankings.
Did you check your site for duplicate content issues? If present, what methods are you going to use to sort them?
Comments (195)