
Hast Du Dir jemals Sorgen um duplizierten Inhalt gemacht?
Das könnte alles sein: Ein Textbaustein auf Deiner Seite oder eine Produktbeschreibung, die Du Dir von einem Markeneigentümer geliehen hast. Oder vielleicht ein Zitat, das Du von Deinem Lieblingsblogger oder einer bekannten Webseite kopiert hast.
Egal wie sehr Du auch versuchst immer 100% Originalinhalte zu veröffentlichen – Du kannst es nicht schaffen.
Duplizierter Inhalt befindet sich unter den Top 5 SEO-Problemen, mit denen Webseiten konfrontiert werden.

Und so scheint es ein Ding der UNMÖGLICHKEIT, alle Duplikate von Deiner Seite zu entfernen.
Selbst Matt Cutts von Google musste einsehen, dass Duplikate überall und immer im Netz auftauchen.
Und Google hat vollstes Verständnis dafür.
Deswegen wird es auch nicht von Google bestraft.
Ja, Du hast richtig gelesen.
Google bestraft keine Webseiten, auf denen sich duplizierter Inhalt befindet und dass Google den Seiten mit mehrfach kopiertem Inhalt nachgeht, ist auch ein SEO-Mythos.
Jetzt fragst Du Dich bestimmt, was der ganze Wirbel um duplizierten Inhalt soll, wenn Google das gar nicht bestraft.
Google bestraft zwar keine Webseite mit dupliziertem Inhalt, rät aber strikt davon ab. Warum ist das so? Wie kannst Du duplizierten Inhalt auf Deiner Webseite vermeiden?
Doch vorab sehen wir uns Googles Definition zu dupliziertem Inhalt an.
Was ist duplizierter Inhalt
Google definiert duplizierten Inhalt wie folgt:
Beim Duplicate Content spricht man im Allgemeinen von umfangreichen Artikeln, die anderen Artikeln auf derselben oder einer anderen Domain gleichen oder auffällig ähneln.
Wie Du anhand von Googles Definition sehen kannst, teilt Google dupliziertem Inhalt in zwei verschiedene Kategorien ein. In Kategorie 1 geht es um ein und dieselbe Webseite und in der zweiten um andere Domains.
Hier ein paar Erklärungen zum besseren Verständnis der Kategorien.
Beispiele von dupliziertem Inhalt
Ich bin mir sicher, dass diese Kategorie auch auf Deiner Webseite auftritt.
Stell Dir vor, ein und derselbe Text erscheint mehrfach auf Deiner Webseite an verschiedenen Stellen.
Das könnte passiert sein:
- Der Inhalt, der auf Deiner Website erscheint, hat verschiedene Adressen (URLs)
- Oder, man erreicht ihn auf verschiedenen Wegen (daher auch die verschiedenen URLs). Das könnten zum Beispiel die gleichen Artikel sein, die bei einer Suchanfrage angezeigt werden, die sich jedoch in verschiedenen Kategorien und Tags befinden.
Dazu sehen wir uns einige Beispiele zum Thema duplizierter Inhalt auf derselben Seite an.
Boilerplate Inhalte
Es klingt einfach, aber Boilerplate-Textbausteine gibt es in verschiedenen Bereichen oder Seiten auf Deiner Domain.
Ann Smarty unterscheidet bei Boilerplate Inhalten zwischen:
- Notwendig für die globale Navigation (Home, Über uns, etc.)
- Bestimmte Bereiche – besonders, wenn Links involviert sind (blogroll, navbar)
- Markup (Javascript, CC ID/Klassen-Namen wie Header, Footer)
Auf einer Standardseite findet man meistens eine Überschrift, eine Fußzeile und eine Seitenleiste. Zusätzlich zeigen viele Content-Management-Systeme (CMS) automatisch die neusten, sowie die am meist gelesenen Posts an.
Wenn Deine Seite von Such-Bot durchsucht wird, wird der Inhalt mehrfach gefunden und das entspricht in der Tat dupliziertem Inhalt.
Dieser Fall von dupliziertem Inhalt schadet Deiner SEO jedoch nicht. Suchmaschinen sind klug genug, um das zu filtern. Es schadet Dir nicht. Du befindest Dich auf sicherem Terrain.
Uneinheitliche URL-Strukturen:
Sieh Dir die folgenden URLs genau an:
www.yoursite.com/
yoursite.com
https://yoursite.com
https://yoursite.com/
https://www.yoursite.com
https://yoursite.com
Sehen sie für Dich gleich aus?
Ja, richtig! Die Ziel-URL ist die gleiche. Jedenfalls sieht es so aus. Dem ist aber leider nicht so: Suchmaschinen filtern sie als verschiedene URLs.
Wenn Suchmaschinen allerdings denselben Inhalt auf zwei verschiedenen URLs: https://yoursite.com und https://yoursite.com feststellen, sehen sie das als duplizierten Inhalt.
Das Problem taucht auch bei URLs auf, die für die Rückverfolgung erstellt wurden:
URLs mit Tracking Parametern können auch duplizierten Inhalt verursachen.
Landesspezifische Domains:
Mal angenommen, Du hast zwei unterschiedliche Internetseiten und jede Domain ist länderspezifisch.
Du hast vielleicht die .de Version für Deutschland und die .au Version für Australien.
Dann ist es normal, dass sich der Inhalt überschneidet. Solange Du den Inhalt nicht übersetzen lässt, finden Suchmaschinen auf beiden Seiten dupliziertem Inhalt.
In diesem Fall wird der Person, die Dich sucht, eine der beiden Seiten angezeigt.
Google erkennt meistens die Herkunft des Suchenden. Nehmen wir mal an, er ist in Deutschland. Google zeigt dann standardmäßig die .de Domain. Jedenfalls in der Theorie, das funktioniert aber leider nicht immer.
Beispiele für duplizierten Inhalt auf verschiedenen Seiten
Kopierter Inhalt:
Google sieht das Kopieren des Inhalts von einer Seite ohne Erlaubnis als Verstoß an. Wenn Du also einfach nur einen kopierten Inhalt veröffentlichst, bewegst Du Dich auf dünnem Eis.
Content Curation:
Content Curation ist das Selektieren und Zusammenfügen von Geschichten, die auf Deine Leser zugeschnitten sind. DieseGeschichten sind von überall aus dem Internet zusammengetragen.
Da ein Post mit Content Curation immer Teil von anderen Inhalten aus dem Internet ist, ist es sehr wahrscheinlich, dass dieser als duplizierter Inhalt angezeigt wird. Auch wenn es sich nur um die Überschrift handelt. Fast alle Blogs bedienen sich der Zitate und Inhalte anderer Autoren.
Auch das sieht Google nicht als SPAM.
Wenn Du immer eine neue Perspektive bereitstellst, Erklärungen verfasst oder Dinge in Deinem eigenen Stil darstellst, wird Google dies nicht als böswillig duplizierten Inhalt betrachten.
Content Syndication:
Content Syndication wird zunehmend zu einer Marketing-Taktik im Mainstream. Curata ermittelte, dass der ideale Marketing-Mix eine 10%ige Verteilung an Syndicate Content enthält.
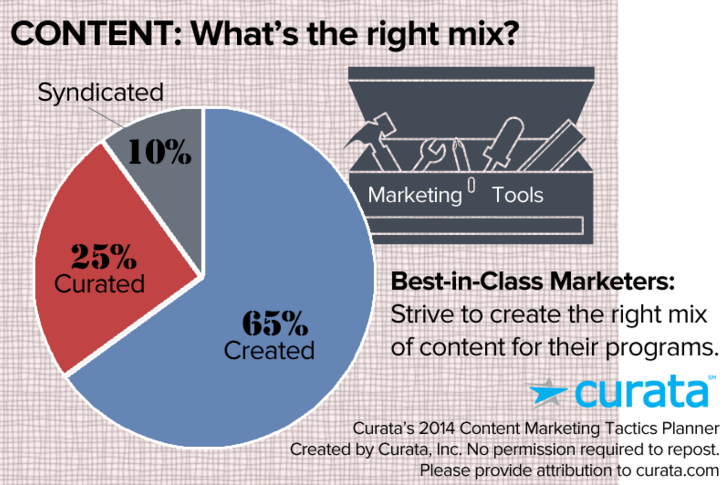
So beschreibt es Search Engine Land: „Content Syndication lässt Deinen Blog, Deine Webseite oder Dein Video auf einer Webseite Dritter stärker hervortreten – als einen vollwertigen Artikel, Link oder Thumbnail.“
Webseiten, die Syndicate Content nachgehen, veröffentlichen ihren Inhalt auf mehreren Seiten. Das bedeutet, dass mehrere Kopien von allen Artikeln existieren.
Die Huffington Post zum Beispiel erlaubt Syndicate Content. Jeden Tag werden hier Geschichten aus dem gesamten Internet mit Genehmigung veröffentlicht.
Auch Buffer betreibt Syndicate Content. Deren Inhalt wird auf Seiten wie Huffington Post, Fast Company Inc. und anderen neu veröffentlicht .
Der folgende Screenshot zeigt den Traffic, den Syndicated Content auf ihre Seite bringt.
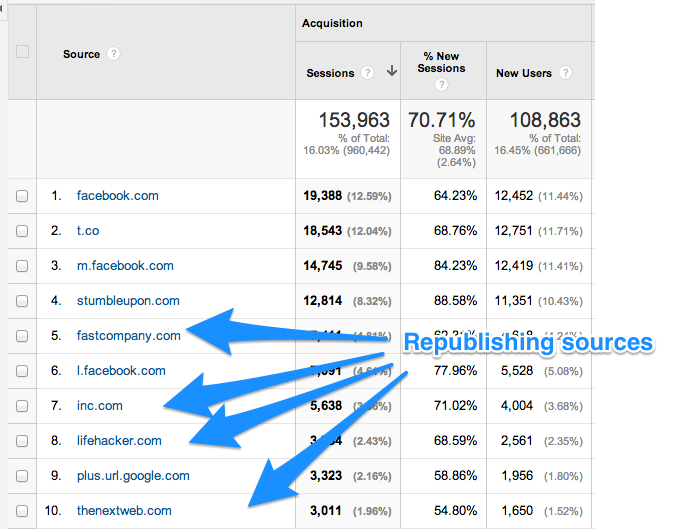
Und obwohl diese Fälle als duplizierter Inhalt gezählt werden, wird Google sie nicht bestrafen.
Der beste Weg um mit Syndicate Content zu arbeiten, ist die Publisher-Websites anzusprechen, ob sie Deinen Inhalt als Original kennzeichnen bzw. ob sie einen Backlink zur Orginal-Seite setzen könnten.
Content Scraping:
Content Scraping ist eine Grauzone, wenn es um duplizierten Inhalt geht.
Wikipedia definiert Web Scraping (oder Content Scraping) als:
Web Scraping (Web Harvesting oder Web-Data Extrahierung) ist eine Softwaretechnologie, die Informationen von Seiten extrahiert.
Interessanterweise „scraped“ sogar Google und bietet sofort mit dem ersten Suchergebnis (SERP) Scraped Data an.
Also ist es kein Wunder, dass Matt Cutts twittert:
Falls eine Scraper URL eine Originalquelle im Ranking übertrifft, dann sag uns Bescheid
Und das verursachte einen ziemlichen Wirbel.
Dan Barker antwortete auf diesen Tweet:
@mattcutts Ich denke, ich habe einen entdeckt. Man sieht die Ähnlichkeiten im Inhalt:
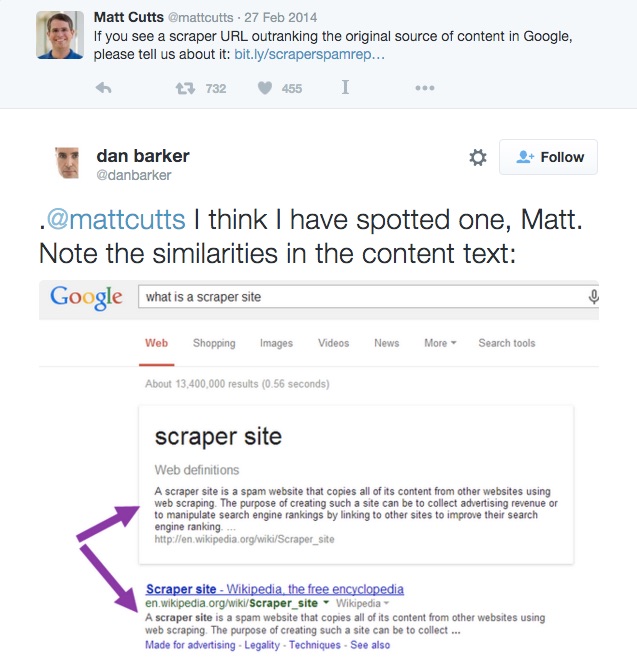
Sieh mal einer an – Google verbindet den Inhalt vom Top Suchergebnis und zeigt es direkt im SERP an! Das ist ohne Zweifel „Content Scraping“!
Demnach ist also nicht jedes „Content Scraping“ Missbrauch.
Dennoch: Google toleriert natürlich keinen Inhalt von Scraper Sites.
Jetzt, da wir uns einen Überblick über duplizierten Inhalt verschafft haben, lass uns die Fälle anschauen, die nicht als duplizierter Inhalt anerkannt werden, die Webmastern aber dennoch oft Sorgen bereiten.
Was nicht als duplizierter Inhalt zählt
Übersetzter Inhalt:
Übersetzter Inhalt is KEIN duplizierter Inhalt. Falls Du eine Internetseite in mehreren Sprachen hast und den Hauptinhalt dann in die jeweiligen Sprachen übersetzt, wirst Du nicht mit Vorwürfen über duplizierten Inhalt konfrontiert.
Okay, dieses Beispiel ist nicht besonders gut, denn falls Du eine Software zum Übersetzen verwendet hast, sogar Google Translator, dann ist die Qualität Deiner Übersetzung nicht unbedingt perfekt.
Und wenn die Übersetzung keinen Sinn ergibt, dann kann Google das möglicherweise als duplizierten Inhalt und Spam betrachten.
Solche Inhalte können zum Glück leicht als „software-generiert“ erkannt werden und dann von Google entsprechend gekennzeichnet werden.
Der beste Weg, um dies zu vermeiden, ist einem menschlichen Übersetzer den Job zu überlassen. Oder benutz eine gute Software und lass das Ganze dann von einem professionellen Übersetzer kontrollieren.
Bei der Überprüfung von übersetzten Seiten musst Du sicherstellen, dass der Inhalt von Top Qualität ist, und dann wird auch Google nicht denken, dass es sich um duplizierten Inhalt handelt.
Falls Du aber weder das eine noch das andere tun kannst, dann solltest Du den von der Software übersetzten Inhalt mit Bots, die robot.txt verwenden, blockieren. (Ich zeige Dir im folgenden Kapitel, wie das geht).
Inhalt von mobilen Seiten:
Falls Du keine reaktionsschnelle Seite hast, dann kann es sein, dass Du eine separate mobile Version Deiner Hauptseite entwickelt hast.
Du hast also verschiedene URLs für denselben Inhalt:
http:yoursite.com – Web Version
http.m.yoursite.com – mobile Version
Denselben Inhalt als mobile Seite zu haben, zählt ebenfalls nicht als duplizierter Inhalt. Google hat verschiedene „Such-Bots = Suchroboter“, die mobile Seiten erkennen. Also mach Dir darüber keine Gedanken.
Google kann den duplizierten Inhalt in vielen Fällen erkennen, und ob dies in böswilliger Absicht getan wurde. Du bist niemals in Gefahr, solange Du nicht versuchst, das System zu manipulieren. Aber Du solltest dennoch immer Fälle von dupliziertem Inhalt vermeiden, da sie sich auf Deine SEO auswirken können.
Hier ist ein Beispiel von dupliziertem Inhalt, der Deiner SEO schadet:
Probleme, verursacht durch duplizierten Inhalt
Problem Nr. 1 – Schwächung durch Link-Popularität
Wenn Du keine konsistente URL-Struktur für Deine Webseite festlegst, dann werden unterschiedliche Versionen Deiner Seite verteilt, sobald Du mit dem Linkaufbau startest.
Um es zu verdeutlichen. Du hast eine ununterbrochene Quelle ankommender Links erstellt.
Und dennoch wird Dein Page-Autority-Ranking nicht so steigen, wie Du es erwartet hast.
Warum ist die Page-Authority trotz der vielen Links nicht gestiegen?
Vielleicht aufgrund der verschiedenen Backlinks zur Quelle durch die Verwendung unterschiedlicher Versionen von URLs.
Zum Beispiel:
https://www.yoursite.com/resource
https://yoursite.com/resource
https://yoursite.com/resource
und so weiter…
Kannst Du sehen, wie duplizierter Inhalt Deine Chancen auf höhere Page-Authority ruiniert?
Und nur weil die Suchmaschine nicht alle URLs richtig interpretieren konnten, die auf dieselbe Quelle verweisen.
Problem Nr. 2 – Ungleiche URLs werden angezeigt
Wenn Google während des Suchvorgangs identische Seiten oder Seiten mit ähnlicher Herkunft findet, wird nur eine Seite angezeigt. Meistens ist das die geeignetere Version. Aber das ist nicht immer der Fall.
Es kann durchaus sein, dass bei einer bestimmten Suchanfrage eventuell nicht die beste URL Version Deiner Seite angezeigt wird.
Es tätigt zum Beispiel jemand eine Suchanfrage nach Deinem Unternehmen. Welche der folgenden Optionen würdest Du für den Suchenden bevorzugen?
https://yoursite.com
oder https://yoursite.com/overview.html
Sicherlich gefällt Dir die erste Version besser.
Aber Google wählt wahrscheinlich die zweite.
Schlussfolgerung: Versuche duplizierten Inhalt zu vermeiden. Es ist doch immer am Besten, wenn der Nutzer die beliebteste Version Deiner URL sieht.
Problem Nr. 3 – Das Durchforsten des Web durch Webcrawler-Suchmaschinen
Wenn Du weißt, wie Webcrawler funktionieren, weißt Du, dass Google seinen Suchmaschinenroboter nutzt, um zu sehen, wie oft Du etwas neues veröffentlichst.
Jetzt stell Dir vor, die Webcrawler von Google durchsuchen Deine Seite und finden 5 URLs, die alle denselben Inhalt zeigen.
Wenn Suchmaschinenroboter ein und denselben Inhalt immer wieder auf Deiner Seite wiederfinden, verliert diese Seite Crawler-Zyklen.
Die Crawler-Zyklen sind nützlich, um neu publizierte Artikel auf Deiner Seite aufzuspüren und einzulesen. Daher verschlechtert es nicht nur Deine Webcrawler-Aktivität sondern auch Deine SEO.
Wie geht Google mit dupliziertem Inhalt um
Wenn Google identische Artikel findet, zeigt es immer nur einen an. Welches Suchergebnis das ist, hängt dabei von der Quelle der Suchanfrage ab.
Hast Du denselben Inhalt auf Deiner Seite und bietest diesen auch als Druckversion an, dann wird das von Google berücksichtigt, wenn der Suchende daran interessiert ist. Wenn man speziell danach sucht, wird nur die Druckversion aufgerufen und angezeigt.
Dir sind vielleicht schon mal Meldungen auf einer SERP aufgefallen, dass ähnliche Suchergebnisse nicht angezeigt wurden. Das passiert, wenn Google sich für eine Seite entschieden hat.
Duplizierter Inhalt wird oft nicht als SPAM betrachtet. Er wird nur zum Problem, wenn er gezielt missbraucht wird und somit die Platzierung in den Suchmaschinen täuscht und manipuliert.
Duplizierter Inhalt wird von Google sehr ernst genommen. Wenn Du versuchst, die Suchmaschinen bei der Nutzung von dupliziertem Inhalt auszutricksen, kann dies zur Sperrung Deiner Seite führen.
Google hat folgende Richtlinien bezüglich duplizierter Inhalte:
Gelegentlich, wenn Google einen Verstoß bei der Nutzung von dupliziertem Inhalt mit der Absicht, die Platzierung zu manipulieren und anderen Nutzern zu schaden, feststellt, wird die Platzierung der betroffenen Seiten korrigiert. Das Ranking kann sich verschlechtern. Tritt der Fall ein und Google entfernt die Webseite vollständig aus dem Index, dann wird sie nicht mehr angezeigt.
Wie Du bereits gelesen hast, geschieht die Nutzung von dupliziertem Inhalt meistens unabsichtlich. Vielleicht hast Du auch einen Boilerplate-Text auf Deiner Seite. Es könnte auch sein, dass andere Seiten sich Deines Inhalts bedienen und ihn ohne Deine Erlaubnis veröffentlichen.
Es gibt verschiedene Möglichkeiten, Deine Seite auf duplizierten Inhalt zu überprüfen. Sehen wir uns einige Optionen an.
Das Erkennen von dupliziertem Inhalt
Methode Nr. 1: Einfache Googlesuche
Der einfachste Weg, duplizierten Inhalt zu erkennen, ist eine Suche mit Google.
Such mit Deinen Keywords und schau Dir die Suchergebnisse genau an. Wenn Google eine unbekannte URL mit Deinem Inhalt zeigt, hast Du duplizierten Inhalt.
Methode Nr. 2: Such nach Warnmeldungen in Google Webmaster
Die Google Search Console warnt Dich auch, wenn der Verdacht eines duplizierten Inhaltes auf Deiner Seite besteht.
Um Google Warnungen über duplizierten Inhalt zu finden, logg Dich in Dein Google Webmaster Konto ein. Wenn Du bereits eingeloggt bist, klick einfach auf diesen Link.
Methode Nr. 3: Überprüfe die Webcrawler-Daten im Dashboard Deines Webmasters
Die Webcrawler-Analyse zeigt die Anzahl der Seiten, die Suchmaschinen automatisch auf Deiner Seite erfassen.
Wenn Webcrawler hunderte von Seiten anzeigen, Du aber nur einige wenige hast, benutzt Du wahrscheinlich uneinheitliche URLs. Webcrawler erkennen denselben Inhalt mehrmals, leider aber mit unterschiedlichen URLs.
Um die Daten der Webcrawler zu sehen, logg Dich in Dein Webmaster Konto ein. Klick erst auf Crawl in der linken Spalte und dann auf Crawl Stats, das im erweiterten Menü erscheint.
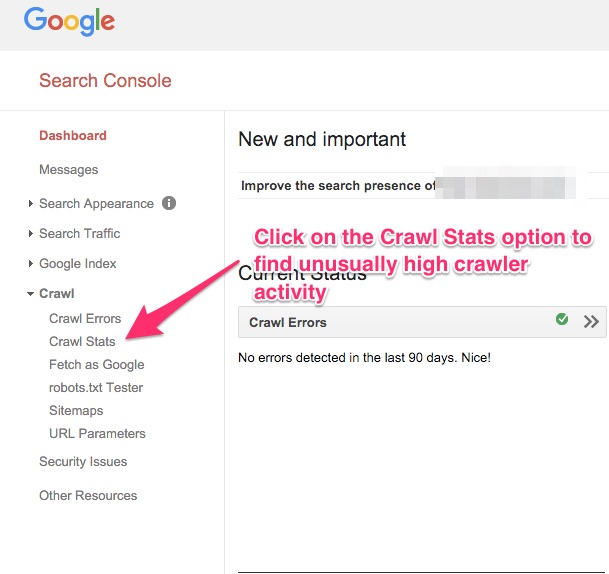
Wenn Du eine ungewöhnlich hohe Anzahl Webcrawler-Daten siehst, solltest Du Deine URL-Aufgliederung ansehen und prüfen, ob Du ungleichmäßige URLs verwendest.
Methode Nr. 4: Screaming Frog Method
Screaming Frog ist ein Desktop SEO-Programm, das Deine Seite wie ein Webcrawler durchleuchtet. Du kannst damit verschiedene Arten von dupliziertem Inhalt aufspüren.
Tipps zum Aufspüren von dupliziertem Inhalt mit Screaming Frog:
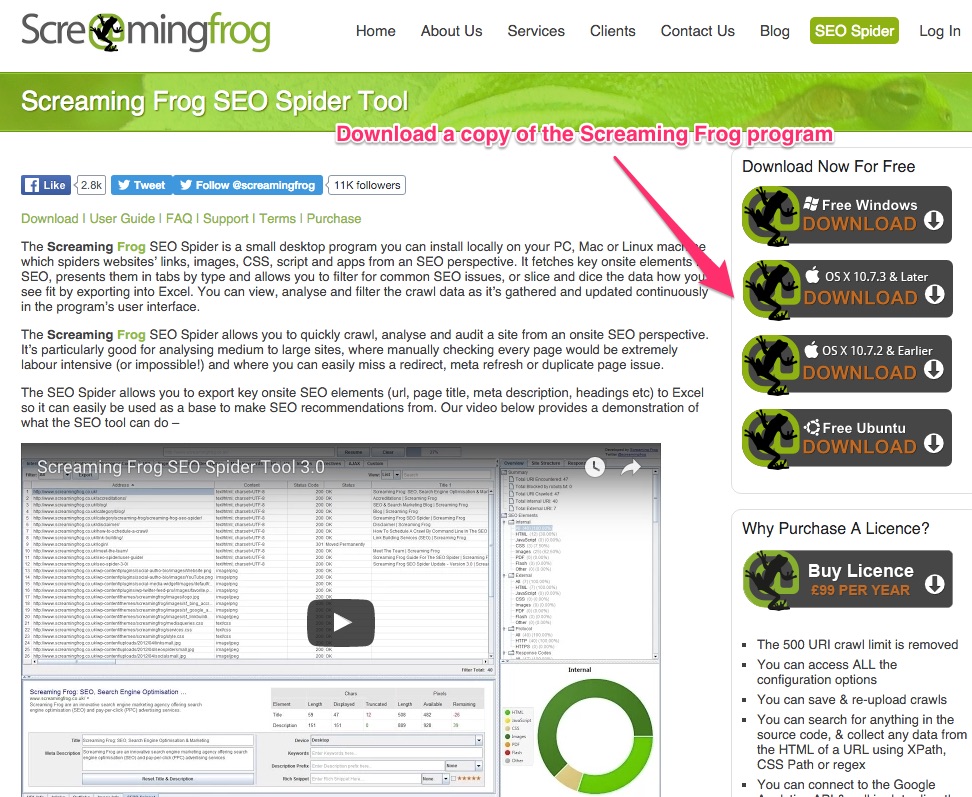
1. Geh auf die Original-Webseite von Screaming Frog und lade Dir die Anwendung herunter.
Screaming Frog hat eine kostenlose Version, die bis zu 500 Seiten durchsucht. Das ist für die meisten Webseiten ausreichend.
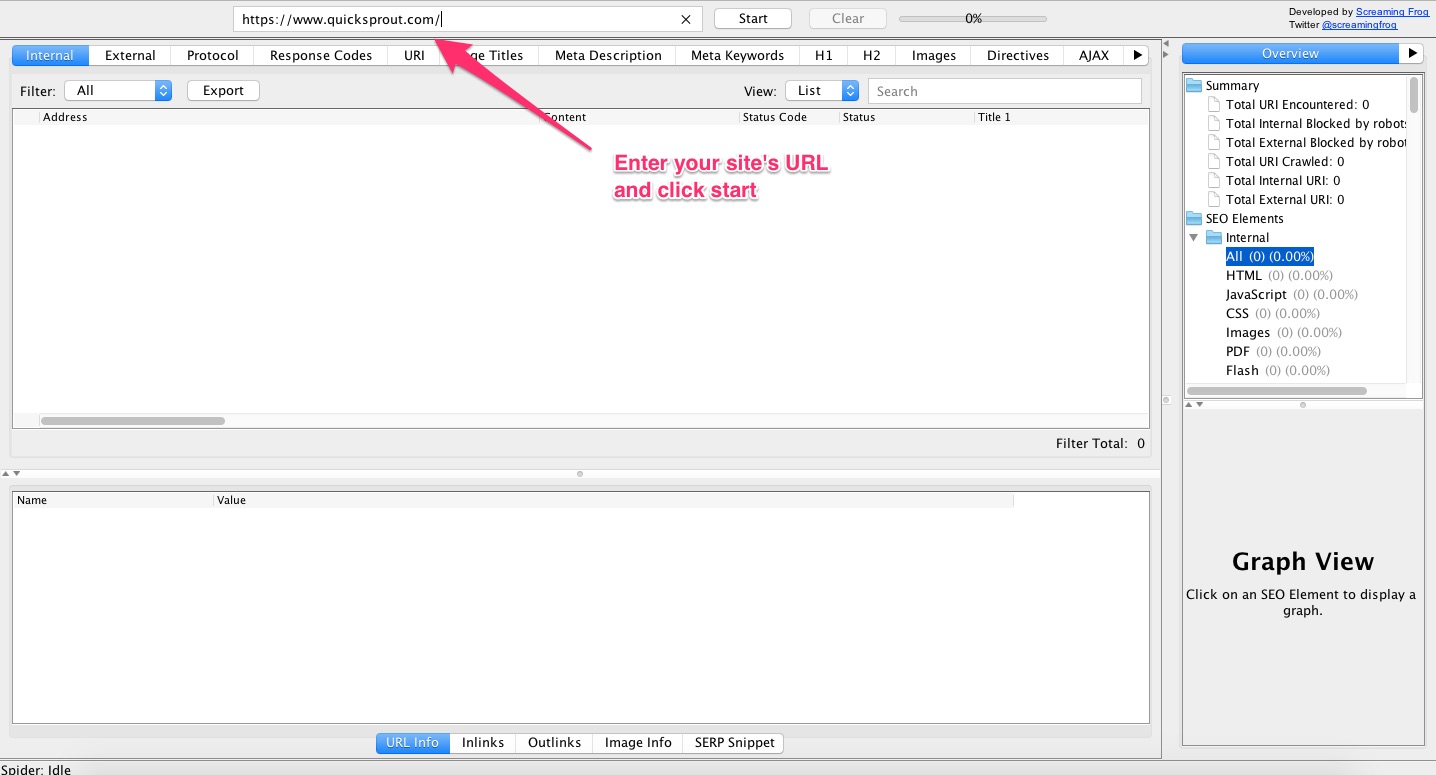
2. Wenn das Programm installiert ist, öffne es und gib die URL Deiner Seite ein. Klick auf Start.
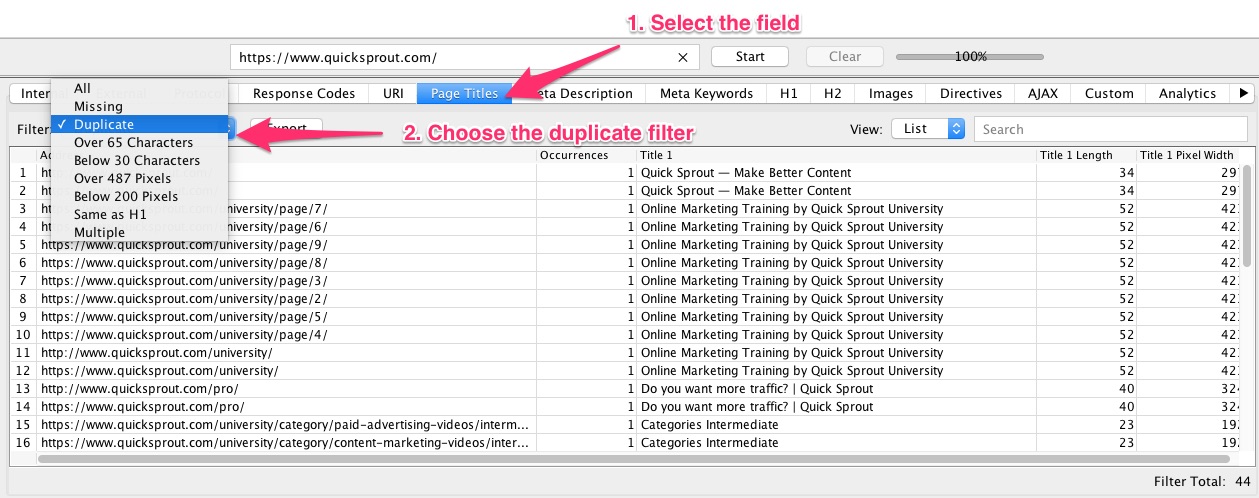
3. Wenn Screaming Frog Deine Seite durchsucht, klickst Du auf den Bereich, den Du auf duplizierten Inhalt überprüfen willst, wie zum Beispiel URLs, Seitennamen, Meta-Beschreibungen etc.
Wenn Du ein Feld ausgewählt hast, bestimme den Duplicate Filter. Bei dieser Methode kannst Du alle Arten von dupliziertem Inhalt auf Deiner Seite erkennen.
Methode Nr. 5: Such nach identischen Inhalten
Diese Methode ist ein bisschen primitiv. Wenn Du aber die Vermutung hast, dass Dein Inhalt von einigen Seiten kopiert wurde oder auf anderen Teilen Deiner Seite wiederzufinden ist, solltest Du das unbedingt überprüfen.
Kopiere einen beliebigen Textblock Deiner Seite. Schick ihn durch den Google Suchlauf. Wähle aber keinen Riesenartikel aus, da das eine Fehlermeldung verursacht.
Wähle 2-3 Sätze und begib Dich auf die Suche.
Wenn in den Suchergebnissen verschiedene Seiten erscheinen, die Deinen Artikel veröffentlicht haben, bist Du wahrscheinlich zum Plagiat-Opfer geworden.
Wenn Du diese Methoden verwendest, filterst Du den duplizierten Inhalt schnell heraus. Lass uns das Problem angehen.
4 Lösungen zum Umgang mit dupliziertem Inhalt
1. Konsistenz
Wie Du in einem früheren Abschnitt sehen konntest, kommt ein Großteil von dupliziertem Inhalt zustande, wenn die URL-Struktur nicht konsistent ist.
Die beste Lösung ist die Standardisierung Deiner Link-Struktur. Das könnte sowohl die www- als auch die nicht www-Version sein. Oder vielleicht die HTTP bzw. die HTTPs Variante – was immer es ist, es muss konsistent sein.
Du kannst Google Deine bevorzugte URL-Version durch die Einstellungen Deiner Präferenzen im Google Webmaster-Konto mitteilen.
Nach dem Einloggen, klick auf die Einstellungen in der oberen rechten Ecke. Danach wähle Seiten-Einstellungen
Hier kannst Du die Optionen der bevorzugten Domain-Einstellungen sehen.
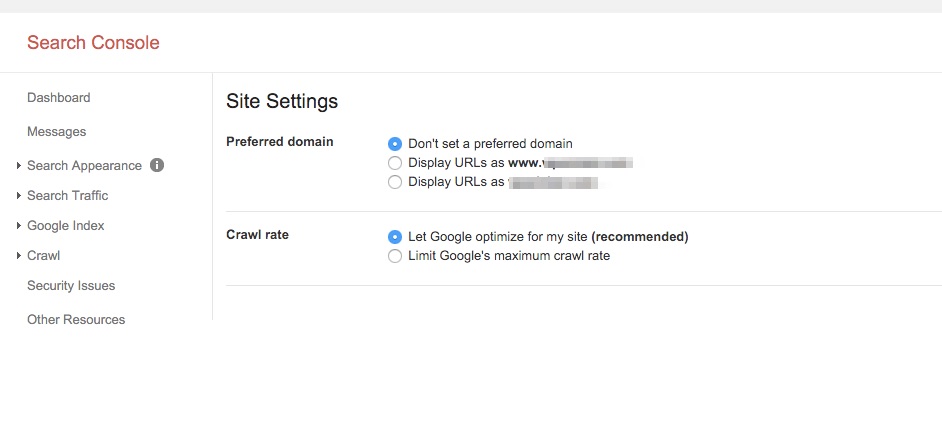
Vorteile der bevorzugten Domain:
- Sortierung von Problemen, die durch www und nicht-www Versionen verursacht wurden
Du weißt, dass Google yoursite.com und www.yoursite.com als zwei verschiedene Seiten behandelt und den Inhalt demzufolge als Duplicate Content wertet.
Durch das einfache Setzen der bevorzugten Domain, teilst Du Google mit, welche zum Web-Crawlen und Indizieren vorgesehen ist. Somit sinkt auch das Risiko für duplizierten Inhalt.
- Beibehalten von Link Juice
Das Setzen einer bevorzugten Domain hilft Deiner Seite, Link Juice zu speichern, auch wenn eine Backlink-Seite zu einer nicht bevorzugten Seite verlinkt wird.
Hier ist ein Auszug aus einer Google-Quelle:
Wenn Du Deine bevorzugte Domain als https://www.example.com festlegst und wir finden einen Link zu Deiner Seite, die als https://example.com formatiert ist, wird der Link https://www.example.com bevorzugt. Googles bevorzugte Domain-Option behandelt ziemlich viele der Unstimmigkeiten mit www und nicht-www Versionen Deiner Seite.
Nach dem Setzen der bevorzugten Domains im Google Webmasters Tool, solltest Du als nächstes die 301 Weiterleitungen von all den unbegehrten Domain-Links zu Deinen bevorzugten URLs veranlassen. Das ist der beste Weg, Suchmaschinen und Besucher auf diese Seite aufmerksam zu machen.
Allerdings kann es, wie oben erwähnt, andere Ungereimtheiten geben. Um diese auszuschließen, solltest Du nicht die bevorzugte URL wählen. Nimm den Syntax den Dein Team nutzt, wenn irgendein Inhalt mit Deiner Seite verlinkt wird.
Du kannst auch einen Style-Guide zur Hilfe nehmen, der Dir zeigt, wie man die URLs generell teilt. Wann immer Du einen Link zu einer beliebigen Seite oder einem Post teilst, solltest Du sicher stellen, dass das Link-Format eingehalten wird.
Hier noch mal zur Erinnerung, wie Suchmaschinen unterscheiden: https://www.yoursite.com/page/ und https://www.yoursite.com/page und https://www.yoursite.com/page/index.htm. Wähle ein Format aus und behalte es bei.
2. In Form bringen
Die meisten CMS erlauben es Dir, Inhalte mit Tags und Kategorien zu versehen. Wenn Nutzer eine Tag oder Kategorie basierte Suche durchführen, wird oft dasselbe Ergebnis angezeigt. Die Suchmaschine nimmt an, dass beide URLs denselben Inhalt haben.
https://www.yoursite.com/some-category
und
https://www.yoursite.com/some-tag
Dieses Problem ist schwerwiegender auf E-Commerce-Seiten, au denen ein einzelnes Produkt durch verschiedene Filter erreicht werden kann (somit auch mehrere mögliche URLs).

Es ist zwar richtig, dass Kategorien, Tags, Filter und Suchboxen helfen, Deinen Inhalt zu organisieren und es einem Besucher erleichtern, zu finden, was er sucht.
Aber wie Du in dem Screenshot oben erkennen kannst, resultieren solche Suchen in verschiedenen URLs und verursachen damit Probleme mit duplizierten Inhalten.
Wenn Leute auf Google suchen, können diese Links Verwirrung bei den Suchmaschinen stiften und das kann dazu führen, dass Google am Ende eine nicht unbedingt benutzerfreundliche Version Deiner URL zeigt, z.B. https://www.yoursite.com/?q=search
Um dieses Problem zu vermeiden, empfiehlt Google, dass Du einen Canonical-Tag zu Deiner bevorzugten URL hinzufügst.
Wenn eine Suchmaschine auf die Seite gelangt und einen Canonical-Tag findet, dann bekommt die Suchmaschine den Link zur original Quelle. Außerdem werden alle Links zu einer beliebigen duplizierten Seite als Link zur Originalquelle gezählt. Und dadurch verlierst Du keinen SEO-Vorteil mehr.
Kanonisierung (engl. Canonicalization) kann auf verschiedene Weise umgesetzt werden:
Methode Nr. 1: Einstellung der bevorzugten Version www und nicht-www
Die Einstellung der bevorzugten Version Deiner Domain, so wie wir es im oberen Abschnitt diskutiert haben, ist auch eine Form von Kanonisierung.
Allerdings behandelt das nur einen Teil dieses umfangreichen Themas. Es bewältigt keinen duplizierten Inhalt, der durch CMS generiert wird.
Methode Nr. 2: Manuelle Zuweisung des Canonical-Links für alle Webseiten
Bei dieser Methode solltest Du damit beginnen, eine Originalquelle zu definieren. Die Originalquelle ist die Seite, die Du Deinen Lesern über die Suchergebnisse zu jeder Zeit zugänglich machen möchtest.
Die Originalquelle ist also auch die Seite, die Du als Deine bevorzugte URL darstellen solltest, um es den Suchmaschinen zu signalisieren.
Verwende die Methoden aus den oberen Abschnitten, um möglichen duplizierten Inhalt auf Deiner Seite zu erkennen. Als nächstes identifiziere die Seiten, die ähnliche Inhalte enthalten und wähle die Originalquelle für jede von ihnen.
Nach den oben genannten Schritten bist Du soweit, die Canonical-Tags zu verwenden.
Um das zu tun, musst Du Zugang zum Quell-Code Deiner bevorzugten Seite haben, und dann im <Head> Tag die folgende Zeile hinzufügen:
<link rel=“canonical“ href=“https://yoursite.com.com/category/resource“ />
In diesem Fall ist „https://yoursite.com.com/category/resource“ die Seite, die Du als Originalquelle festlegen willst.
Du musst dann den Prozess für jede ähnliche Seite wiederholen.
Mein Blog auf CrazyEgg unterstützt Kategorien. Meine Posts werden sowohl in der Blogroll auf der Homepage, als auch in einzelnen Kategorien gefunden.
Ich verwende den rel=canonical Tag, um meine bevorzugte URL für die entsprechende Seite, bzw. den Post, zu markieren.
Sieh Dir den Screenshot mit dem hervorgehobenen Tag an:
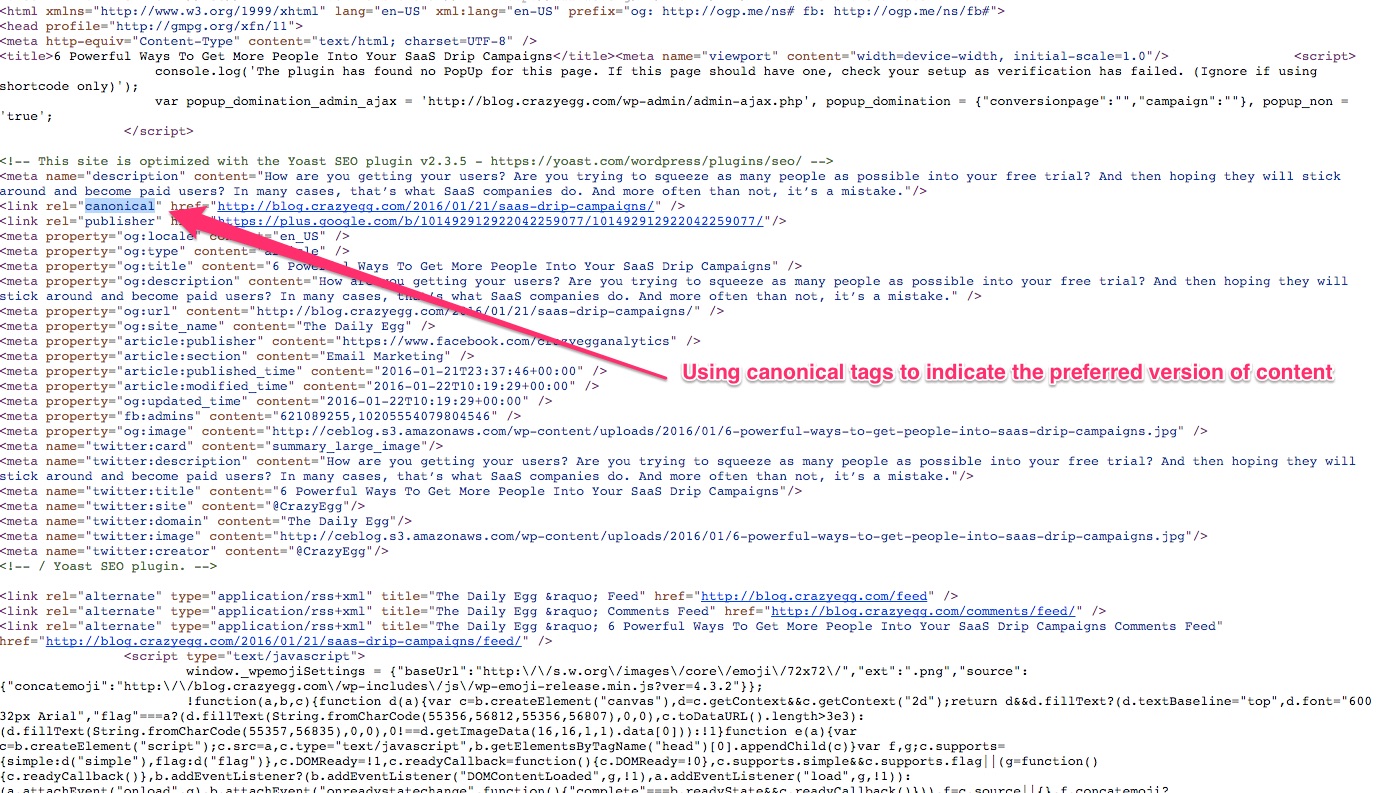
Wenn Du den Canonical-Tag verwendest, ist das eine gute Gelegenheit um Google zu zeigen, welchen Link Du bevorzugst und welchen Google anzeigen soll, wenn danach gesucht wird.
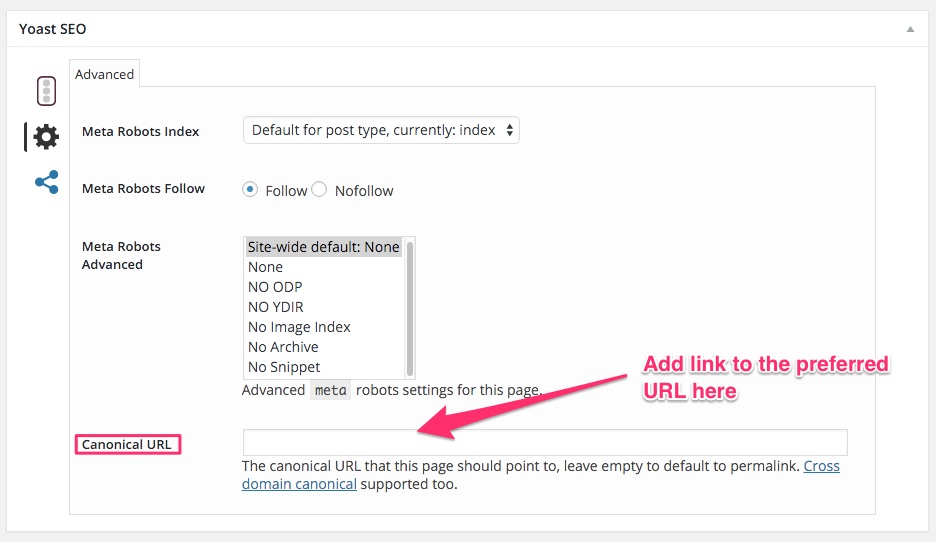
Wie Du wahrscheinlich bemerkt hast, nutze ich WordPress. Ich verwende das Yoast SEO-Plugin. Dieses Plugin filtert die bevorzugte Version Deiner Artikel oder Seiten. So werden Bedenken bezüglich des Erscheinens mit verschiedenen URLs ausgeräumt.
Wenn Du Deine Seite mit WordPress machst, empfehle ich Dir diesen Plugin. Du findest die Canonical URL-Auswahl unter den erweiterten Plugin Einstellungen (engl. Advanced Plugin Settings).
Wenn Dein Post oder die Seite, die Du einstellst, schon Deine bevorzugte Seite ist, lass das Feld Canonical URL-Tag einfach frei. Wenn dem nicht so ist, ergänze die bevorzugte Quelle im Canonical URL-Feld.
Methode Nr. 3: Einrichtung einer 301-Weiterleitung
Duplizierter Inhalt taucht oft bei der Neugestaltung von Internetseiten auf. Die Neubildung von Links kann mehrere Kopien vom selben Inhalt erzeugen.
Um die Gefahren des duplizierten Inhalts zu reduzieren, richte eine 301 Weiterleitung ein. Die 301 Weiterleitung von einer nicht bevorzugten URL, zu einer favorisierten URL ist der beste Weg, den Suchmaschinen Deine Priorität zu signalisieren.
Wenn eine automatische Suchmaschine eine Seite mit einer 301 Weiterleitung entdeckt, stößt diese dabei auf die Originalseite mit dupliziertem Inhalt. In diesem Fall werden alle Links zu den duplizierten Seiten als Link zu den Originalseiten behandelt. (Dein SEO verschlechtert sich nicht.)
Es hängt von Deiner Seite ab, wie Du die 301 Weiterleitung nutzt: Wenn Du Fragen zur Anwendung von Weiterleitungen hast, wende Dich an Deinen Webhost.
Wenn Du WordPress nutzt, kannst Du einen Plugin wie Redirection nutzen, um eine 301 Weiterleitung einzurichten.
Welche Methode Du auch immer nutzt, ich empfehle Dir, diese vorher bei einem Link zu testen. Das Einstellen einer Umleitung kann schnell schief gehen.
3. Noindex Meta-Tag
Für den Webmaster sind Meta-Tags eine gute Gelegenheit, den Suchmaschinen wichtige Informationen über die entsprechende Seite zu liefern.
Der Noindex Meta-Tag signalisiert der Suchmaschine, eine bestimmten Quelle nicht zu untersuchen.
Oft werden der Noindex Meta-Tag und der Nofollow Meta-Tag verwechselt. Der Unterschied zwischen Beiden ist, wenn Du den Noindex und den Nofollow Tag benutzt, hältst Du die Suchmaschinen davon ab, die Seite zu registrieren und ihr zu folgen.
Nutzt Du aber den Noindex und die Follow Tags, signalisierst Du den Suchmaschinen Deine Seite nicht zu registrieren, die Links zur bzw. von der Seite jedoch nicht zu übersehen.
Du kannst den Noindex Meta-Tag einsetzten, damit die Suchmaschinen Deine Seite nicht als duplizierten Inhalt einstufen.
Wenn Du den Meta-Tag einsetzt, um jegliche Art von dupliziertem Inhalt zu vermeiden, solltest Du folgenden Code in den Head-Tag der Seite einfügen.
<Meta Name=”Robots” Content=”noindex,follow”>
Wenn Du den Follow Tag mit dem Noindex Tag anwendest, kannst Du Dir sicher sein, das Suchmaschinen die Links mit dupliziertem Inhalt nicht ignorieren.
4. Der Hreflang-Tag zur Verwaltung länderspezifischer Seiten
Wenn Du übersetzten Inhalt veröffentlichst, achte auf den Hreflang-Tag. Die Suchmaschinen können die geeignetere Version Deiner Seite dann besser finden.
Wenn Du Deine englische Seite also ins Spanische übersetzt hast, ergänze diese Markierung “<link rel=“alternate“ href=“https://example.com“ hreflang=“en-es“ />” in der spanischen Version.
Diese Ergänzung solltest Du bei allen länderspezifischen Seiten vornehmen. Dadurch verhinderst Du, dass die Suchmaschinen diese als duplizierten Inhalt erkennen. Es ist aber vor allem auch benutzerfreundlicher, wenn Leute Deine Seite in ihrer Landessprache aufrufen.
5. Verwende den Hashtag anstelle des Fragezeichens bei UTM-Parametern
Es werden häufig Tracking-Parameter benutzt, um Quellen und Publikum herauszufinden. Das ist ein Hilfsmittel zur Analyse und Verbesserung der Effektivität.
Wie wir jedoch bereits erwähnt haben, wenn Du einen Link wie diesen hier erstellst: https://yoursite.com/?utm_source=newsletter4&utm_medium=email&utm_campaign=holidays, erkennen und melden Suchmaschinen diesen als duplizierten Inhalt.
Um dem Abhilfe zu verschaffen, benutzt das # Zeichen als Alternative zum Fragezeichen. Wenn Suchmaschinen ein # in einer URL sehen, ignorieren sie alles Folgende und Probleme mit dupliziertem Inhalt werden vermieden.
6. Vorsicht mit Content-Syndication
Wenn Du anderen Seiten die Erlaubnis gibst, Inhalte Deiner Webseiten erneut zu veröffentlichen, musst Du unbedingt auf eine Verlinkung zu Deiner Seite bestehen. Bestehe bei der Verwendung Deiner Artikel auf einen Rel-Tag oder auf einen Nointex Tag. So können duplizierte Inhalte gleich vermieden werden.
Wie gehst Du mit dupliziertem Inhalt um
Wie ich bereits erwähnt habe, taucht duplizierter Inhalt immer wieder auf. Wenn Du auf Deiner Seite auch fündig geworden bist, musst Du sofort handeln. Ich habe Dir verschiedene Wege gezeigt.
Was ich noch nicht erwähnt habe, sind Dinge, die Du auf keinen Fall tun solltest, um Probleme mit dupliziertem Inhalt zu beheben.
1. Blockiere keine URL mit robots.txt
Zuerst, was ist robot.txt? Robots.txt ist eine Textdatei, die von Webcrawlern beim Suchlauf gelesen wird. Mit dieser Datei kann man das Durchsuchen bestimmter URLs verhindern.
Einige Webmaster geben URLs, die Robot.txt Dateien enthalten, als duplizierten Inhalt an. Auf diese Weise wollen sie Suchmaschinen vom Crawling abhalten.
Google verurteilt alle Maßnahmen, die Webcrawler in irgendeiner Weise vom Durchsuchen abhalten. Google nimmt sie als Seiten mit einmaligem Inhalt wahr, obwohl sie es wahrscheinlich nicht sind, sondern Seiten mit dupliziertem Inhalt.
Ein weiterer Einwand bei dieser Blockade ist, dass andere Seiten eventuell mit einer geblockten Seite verlinkt werden. Wenn eine beliebte Seite mit einer geblockten Seite verlinkt ist, erfassen und erkennen Suchmaschinen diese Seite nicht. Du erhältst dann nicht das SEO, das Dir von diesem Backlink zusteht.
Es besteht immer die Möglichkeit, die duplizierte Seite mit einem Canonical-Tag zu markieren.
2. Formuliere Inhalt nicht um, oder verdrehe die Wörter, um ihn einzigartig erscheinen zu lassen.
Google Roboter erkennen umformulierte oder bot-generierte Inhalte. Umgestellte Sätze oder Wortverdrehungen, um dem Text ein neues Aussehen zu geben, haben keinen Erfolg. Posts mit verdrehtem Inhalt werden von Suchmaschinen erkannt. Du wirst in den Suchmaschinen als jemand vermerkt, der Suchergebnisse manipuliert. Das kann dann dazu führen, dass Google Maßnahmen gegen Deine Seiten ergreift.
3. Nutze nicht die “remove URL” Option in Google Webmasters
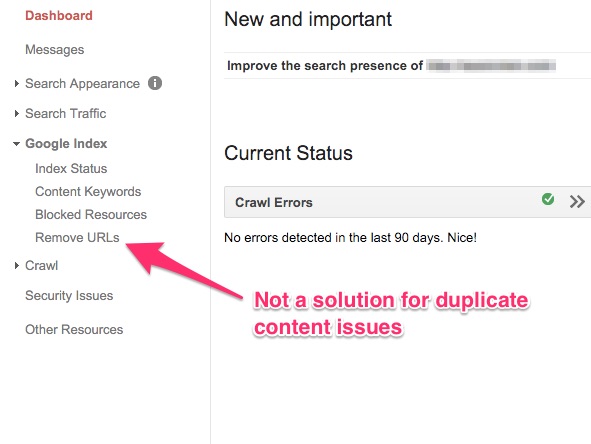
Hast Du bemerkt, dass Google Webmaster Dir die Möglichkeit gibt, URLs von Deiner Seite zu entfernen.
Einige Webmaster wählen leider die benutzerunfreundlichere Version, die in den Suchergebnissen angezeigt wird und machen so Gebrauch von der oben genannten Version.
Das Problem dabei ist, dass die URLs nur kurz verschwunden sind. Deine Seite wird auch weiterhin mit mit allen Problemen auftauchen, die oben erwähnt wurden. Das ist keine zufriedenstellende Lösung.
Diese Funktion ist nur sinnvoll, um vorübergehend etwas von Deiner Seite zu entfernen oder, um das Problem schnell zu beheben. Nur bist Du Zeit hast der Sache auf den Grund zu gehen. Es löst aber nicht das Grundproblem duplizierter Inhalte.
Fazit
Die meisten Probleme mit dupliziertem Inhalt können vermieden oder behoben werden.
Hast Du Deine Seite auf duplizierten Inhalt überprüft? Wenn ja, welche Methoden hast Du Dir ausgesucht?
Generiere mehr Traffic